In the payments ecosystem, we integrate with many external services to complete a transaction. In a way, the uptime and performance of the platform are transiently dependent on external factors like other service partners we integrate with.
Any performance degradation on these external services is beyond our control. One poorly performing external service can bring down the entire platform if resiliency is not built in. Thus, fault tolerance is a key concern when designing microservices.
The Use Case and the Fault
Let’s take this use case for resiliency.
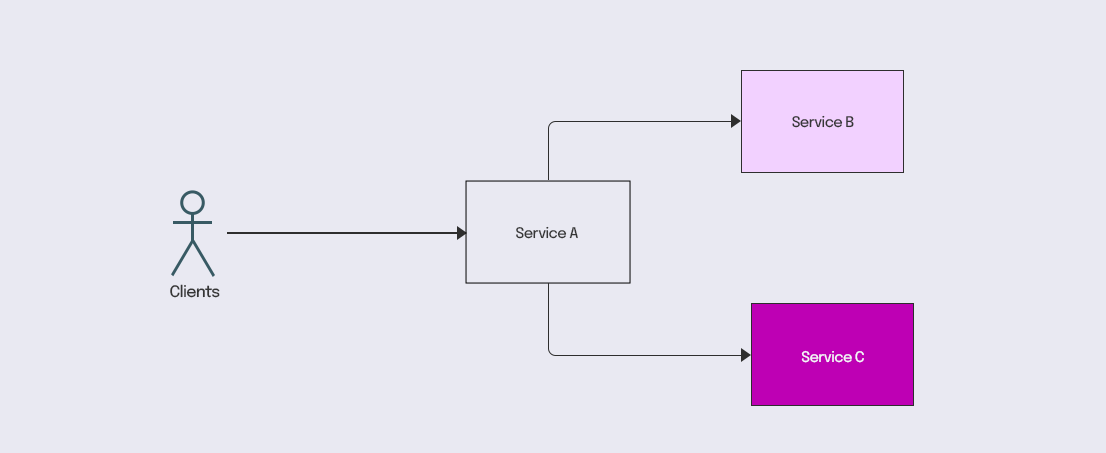
- Let’s say your clients are integrated with Service A, which depends on two downstream services, B and C.
- Service A has ten threads configured and gets two requests per second as incoming traffic.
- Let’s assume that the traffic distribution between Service B and Service C is nondeterministic and is based on the business rules executed on incoming traffic. So Service A will fulfil the incoming requests by routing through either Service B or Service C.
- Now, suppose Service B has a performance degradation at some point and experiences a high latency, but Service C performs normally.
- This will cause the threads of Service A to get blocked for Service B. As a result, the entire thread pool of Service A will get exhausted waiting for a response from Service B.
- Even the Service A to Service C path, which worked normally, gets affected in the process.
Thus, the fault in one downstream service affects the entire ecosystem of Service A, leading to a degraded customer experience.
How to Tolerate the Fault
Several patterns help us build resilient systems. Some of the most common ones are as follows:
- Bulkhead
- Circuit Breaker
1. Bulkhead
This pattern is derived from the bulkheads of a ship’s hull, where water leakage in a ship’s compartment is isolated with a self-sealing ability, preventing the water from leaking to the other compartments. For the fault scenario mentioned above, this typically is a hole in the hull with water sinking the entire ship.
a. Using Dedicated Thread Pools
You can apply the bulkhead pattern to the above use case by having a dedicated thread pool in Service A for each downstream service (Thread pool-B and Thread pool-C).
By isolating the thread pools in Service A, performance issues in Service B will cause only the respective thread pool to be exhausted, thus allowing us to back-pressure. The back pressure can be applied once the thread pool dedicated to Service B is exhausted.
The A -> C path will continue to work normally. You can also use a countdown of semaphores here with a predefined count for each downstream dependency.

b. Using Dedicated Deployments
Using separate deployable units for clients served on paths B and C will provide deployment level isolation and help achieve fault tolerance. However, as the number of downstream services grows, this won’t be easy to operationalise.
2. Circuit Breaker
You may have heard of circuit breakers in electrical circuits. In case of high load, the circuit breaker will trip and save the electrical devices from catching fire. The circuit breaker pattern in software engineering is based on the same principle. You can use it in service interactions by having the traffic flow through a software circuit breaker.
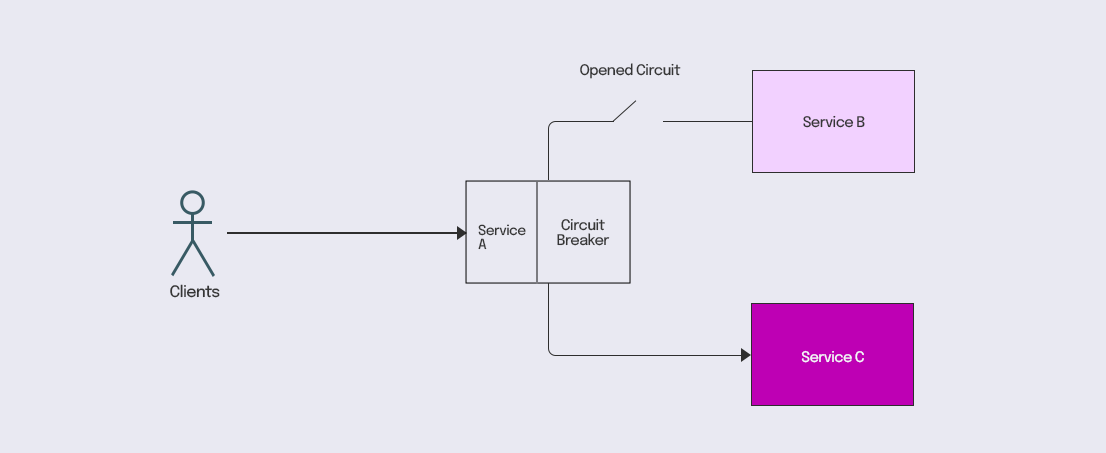
- You can configure the circuit to trip open for a preconfigured percentage or count of failures over a moving time window. Optionally, a fallback behaviour can be provided when circuit trips open.
- When the number of consecutive failures reaches a threshold, the circuit breaker gets activated, and the circuit will remain closed for a preconfigured cool-off window.
- After the cool-off period, the circuit breaker allows a limited number of trials to validate if the circuit is back to normal.
- If the trials succeed, the circuit resumes normal operation, or the cool-off period begins again.
- The circuit can be configured for any scenario that can quantify as a failure, including timeouts when invoking a service, latencies above a threshold, a specific error code, etc.
For the fault use case discussed above, the traffic to Service B and Service C can flow via the circuit breaker with a configured failure threshold. A latency above a point can be configured as a failure in the circuit.
The circuit will trip open on crossing the threshold and immediately fail the transactions via the A->B route. It will effectively prevent the threads in Service A from getting blocked while waiting for a response from Service B, thus providing fault tolerance for Service A. This pattern will shield us from failures in domains beyond our scope of control.
We hope we were able to shed some light on how we build resilience to ensure platform performance at Plural. Stay tuned to read more from the Engineering team. Visit our website for more information, or contact us at pgsupport@pinelabs.com.
Plural by Pine Labs has received an in-principle authorisation from the Reserve Bank of India (RBI) to operate as a Payment Aggregator.
This article is written by Sivashankar Thiyagarajan, Vice President of Engineering at Plural by Pine Labs.

Amrita Konaiagari is a Marketing Manager at Plural by Pine Labs and Editor of the Plural blog. She has over 10 years of marketing experience across Media & Tech industries and holds a Master’s degree in Communication and Journalism. She has a passion for home décor and is most definitely a dog person.